 Figure 1 (8.6K GIF)
Figure 1 (8.6K GIF)
Barbara L. Grabowski and William L. Harkness
The Pennsylvania State University
Journal of Statistics Education v.4, n.3 (1996)
Copyright (c) 1996 by Barbara L. Grabowski and William L. Harkness, all rights reserved. This text may be freely shared among individuals, but it may not be republished in any medium without express written consent from the authors and advance notification of the editor.
Key Words: Active learning; Computers as thinking tools; Learning with technology.
This article reports on the results of two studies that investigated the effectiveness of different uses of expert systems in large introductory statistics classes. Three groups of students were compared -- those who used an expert system created by the instructor of the course, those who created their own expert system, and those who did not use any at all. The first experiment showed non-significant, but interesting, trends that were explored in the second experiment. In the second experiment, significant differences emerged as the semester evolved in favor of those who used the expert system, regardless of whether or not the students created it themselves. These differences disappeared on the final exam, when technological problems added to the end-of-the-semester tension. These findings support the notion that the use of expert systems in the classroom can have an important impact on the level and amount of learning that occurs. This article describes these two studies in detail and draws some implications for teaching.
1 Methods for statistics education are changing -- from the preacher teacher model to one in which students are more active in the learning process. Content for statistics education is also changing from procedural calculation to conceptual problem solving. The literature is rich with discussions about the benefits of these new approaches (Steinhorst and Keeler 1995). The purpose of this article is to present our research on the use of an active learning method enabled by emerging technology, the use of expert systems in the classroom. Students can generate a statistical advisor themselves or use one created by the professor to study expert thinking on a topic.
2 The use of computers for learning is changing as well. The typical model is the computer as teacher or coach in the form of computer-based instruction or computer simulation. Extending this initial conception of computers, researchers now regard them as thinking partners in the learning process -- enabling the learner to be more actively involved in the content. They are seen as amplifiers to and modifiers of one's thinking (Olson 1985; Pea 1985; Salomon, Perkins, and Globerson 1991; Jonassen 1996), and are called computer-based cognitive technologies or thinking tools. These intellectual power tools enable unlimited access to data and support students or other users in their organization and reorganization of data. Students do not simply do more of what they would normally do; they begin to think in new and more powerful ways (Pea 1985). In other words, the computer and the learner function in tandem and think beyond what they were previously able to do. For example, by using the computer, students can rapidly (and visually) understand how various diagnostic tools in regression analysis detect departures from assumptions such as non-constant variance, nonnormality, lack of independence, and the effect of outliers. Without the computer, conceptual understanding of these diagnostics is much more difficult to illustrate or grasp.
3 Besides manipulating data via the computer to visually depict concepts, the statistics student can also learn in partnership with computerized expert systems. Expert systems in general are decision-making tools that function in the same way as human experts in a consultation session. Through a series of data-gathering questions, the expert -- human or otherwise -- ``mulls'' over the responses, combining critical features or aspects of a situation to reach a decision. When a researcher needs advice on which statistical procedure to use, he or she typically consults a human statistical advisor. More recently, both paper-based and computerized systems have provided similar guidance to researchers and students on which methods are most appropriate given a certain type of data, number of experimental groups, and experimental design. See, for example, the ``Guide'' by Andrews, Klem, Davison, O'Malley, and Rodgers (1981), JMP (1996), and Triola (1994). The JMP software is an expert system: it is menu driven, with questions the user must answer in order to have an analysis performed. The text by Triola contains flowcharts to guide students in their selection of statistical procedures.
4 One use of expert systems is to give students a commercially prepared statistical advisor/expert system, but this is only one of several ways expert systems can be incorporated into classroom learning. With advances in computer software and programming languages, expert system shells have been created. An expert system shell enables a non-computer programmer (like a statistics professor or student) to enter appropriate questions and rules in layperson's language and create his/her own expert system. Therefore a statistics professor could create a system tailor-made for his or her classroom and pass it out to each student, along with accompanying exercises to complete. Alternatively, students can use the statistical concepts they are being taught in class to create their own version of a statistical advisor/expert system. Any one of these three alternatives teaches statistics at a high level of conceptual, rather than procedural, understanding and demands a solid grasp of the concepts underlying statistics. For example, the student needs to know the difference between categorical and quantitative data, or between response and explanatory variables, to answer (or create!) the questions in the expert system.
5 Two of these alternatives -- instructor-provided and learner-generated expert systems -- were incorporated into an experimental study to investigate their impact on learning. These are described in greater detail below.
6 The instructor can use an expert system shell to create a statistical advisor that walks students through a series of questions and provides methodological advice at the end. In our study, ten statistical methods formed the basis for the creation of the expert system. These included chi-square and t-tests, regression analysis, and analysis of variance. The rules for selecting from among these methods were generated by the statistics professor; see Appendix A. This expert system was then provided to the students to find which statistical method would be appropriate for a number of statistical scenarios; see Appendix B. The professor's logic behind selecting statistical methods is revealed to the student through the questions that the student is asked in the expert system consultation or data-gathering process. In one case, the student might be asked if the data are categorical or quantitative, how many samples there are, or whether the data are paired or independent. The computer functions as a partner in helping to synthesize the fragments of the thinking into a decision, modeling the professor's thinking.
7 Learner-generated expert systems are, as the name implies, created by the students themselves using an expert system shell. Students need to be taught how to create a knowledge base, enter the rules into the expert system, and create the front end user/computer interface. To generate this expert system, students need to have a firm grasp of both the concepts and the interrelationships of the underlying concepts to form rules for selecting among statistical methods. Students gather information during the course of the semester and create a model of expert thinking.
8 The first step is the creation of the knowledge base. A knowledge base consists of data about objects, rules describing the relationships among those objects, and possible solutions (Grabinger, Wilson, and Jonassen 1990). It is actually at this point that much of the statistical reasoning occurs. We investigated two methods for creating the knowledge base -- a matrix and a decision tree approach.
9 A matrix consists of decisions/solutions, attributes which will differentiate the decision/solutions, and an interrelationship among the attributes and decision/solutions; see Figure 1. The student is encouraged to think first about the alternative decisions, and then the attributes, and then their interrelationships. They then review the matrix to determine if all of the solutions can be reached and if some combinations of attributes are left without solutions.
Figure 1. Example Matrix
10 The second method for generating the knowledge base is to create a decision tree. The decision tree is a hierarchical structure or diagram beginning with a question that has a number of responses which constitute branches off from the main question. Each branch ends in a unique set of conditions that defines one of the particular decision outcomes; see Figure 2. This hierarchy suggests a series of questions that will lead one through the branching structure to the correct outcome.
Figure 2. Example Decision Tree
11 The second step is to enter the rules into the expert system shell. Two ways of entering the data into the expert system shell were explored in this study -- programming the rules and using an induction table. Programming the rules requires the student to understand the syntax for writing ``action'' statements, ``If-then'' rules, and ``display'' statements. The syntax is not complex; however, the student must attend to details like exact spelling and placement of semicolons. An induction table, on the other hand, requires the student to create a matrix of decisions and attributes that are then converted by the expert system to the proper syntax. Using this method, students must be aware of spacing requirements and size limitations of the table.
12 The third and final step is to develop the human-computer interface. The human-computer interface enables the expert system to gather the necessary data on which to base the decisions. These are the questions that are posed to the user, such as, Do you have one or more than one response variable? (Answer: one); Is your response variable qualitative or quantitative? (Answer: quantitative); Is there an independent variable? (Answer: yes); Is it qualitative or quantitative? (Answer: qualitative); How many levels does this qualitative variable have? (Answer: two).
13 While the above three steps are needed to physically create the expert system, there is one more step that is critical to the learning process -- working iteratively with the computer to refine the knowledge base. The computer becomes, as Salomon, Perkins, and Globerson (1991) suggest, a cognitive tool ``with which we work.'' This can happen in a number of ways. We chose to provide students with 30 scenarios matched with solutions. Three scenarios were provided for each of the methods included in the expert system. See Appendix B for a sample of these scenarios. Students used the 30 scenarios to test their expert systems, to see if the systems provided the correct methodological advice.
14 There is limited research available on the relative effectiveness of the two strategies compared here -- having learners construct their own expert system versus providing one already constructed. The research studies that do exist are based on anecdotal data and observation of few subjects and were conducted over short periods of time. They include subjects in a variety of areas -- college students in physics (Trollip and Lippert 1987, Lippert 1988), high school students in biology (Wideman and Owston 1988), nursing students studying alcoholism (Lai 1989), and MBA students (Knox-Quinn 1992). The research indicates that the construction of expert systems engages students in problem solving at a level that requires the use of new or expanded cognitive strategies just beyond what they currently possess. Creating the knowledge base during expert system construction aids in the refinement of domain-specific knowledge, and use of the expert system promotes students' acquisition, practice, and extension of their cognitive and metacognitive skills. Overall, these studies indicate that engaging the learner in the generation of a content-specific expert system holds great promise as an instructional strategy for developing both conceptual and problem-solving skills.
15 A factor that we believe affects learning with expert systems -- especially those created by the students themselves -- is the variability in thinking patterns of students. While many types of differences in thinking styles have been identified, the serialist/holist dimension appears to have the most potential for differentiating success with various methods of expert system construction. For the serialist/holist thinker, the choice between using a decision tree or a matrix for creating the knowledge base may be crucial. According to Ford (1985), a serialist learner thinks in a systematic, linear way, preferring to begin with the details and proceed toward creating a total picture. The holist learner, on the other hand, thinks in a more global or conceptual way, preferring to begin with the big picture and extract details from it. Ford (1985) also identified ``versatile learners,'' who use both types of thinking easily and are comfortable with either expert system construction strategy. This thinking style (serialist/holist) is measured using items in a survey specifically designed by Ford to extract the thinking style preferred by subjects to study and learn. Subjects are classified as holists if they have a high score on this survey, as versatile if their score is in the middle range, and as holists if they have a low score. We have found no research on the effect of thinking styles on learning with expert systems.
16 To add to the existing research base, we conducted two large studies to investigate the instructional effects of learner-generated or instructor-provided expert systems. In the second study, we specifically designed treatments to determine whether a particular expert system construction strategy matched the thinking styles of serialist and holist learners.
Subjects
17 One hundred and twelve students in an elementary statistics course volunteered to participate in this study and were given 15 extra points for participating. They represented a wide range of majors and levels, although most were in their sophomore year. They were randomly assigned to learner-generated, instructor-provided, and control groups. Due to the intensive nature of this study, only 79 subjects remained at the end of the semester. The attrition was mainly in the treatment group that required students to create their own expert systems. A major concern was whether the remaining subjects in that group represented the best and the brightest, which would bias the results. We compared exam scores obtained prior to the study and found no significant differences between the students who remained in that group and those in the other groups. There was no indication that ability was a contributing factor in remaining in the study. However, other characteristics of the dropouts could have created a bias.
Dependent Measures
18 The final exam with a possible score of 200 points was used to test the level of statistical knowledge of each group. A subtest of ten items was also selected in which students were required to select appropriate statistical methods.
Results
19 Analysis of variance was used to test for significant differences among groups on the final exam and the ten-item subtest. There were no significant differences. However, the means on the final exam showed an interesting pattern, with the control group scoring the lowest at 134.2 (sd = 30.7); the instructor-provided group scoring next highest with 141.5 (sd = 26.1), and the learner-generated group scoring highest at 147.3 (sd = 22.4). Mean scores on the subtest showed a different pattern, with the instructor-provided group scoring the highest at 6.3 (sd = 1.8); the learner-generated group next at 5.8 (sd = 2.4), and the control group again scoring lowest with a mean of 5.3 (sd = 2.0).
Discussion
20 Given the high attrition and the observed differences in mean scores, we felt a second study was warranted. The design of the study was refined to insure a greater number of subjects and a longer period of time to train students.
21 Five key modifications were made to the first experiment. The scope of the experiment was expanded to include the entire semester; the treatments were included as a regular activity of the course; the population was expanded to include two large undergraduate statistics classes (425 subjects total); the training was modified to include two types of knowledge construction strategies (matrix and decision tree) and two types of rule-inputting strategies (programming and induction) to accommodate differences between serialist and holist thinking styles; and test data were collected to track the effect of the treatments across the entire semester.
22 This study was conducted in two statistics classes of an elementary course taught by the same instructor. It was a 4-credit course that had three to four lectures and one recitation (laboratory) meeting per week, in a 15-week semester system. Recitation sections were handled by teaching assistants (TA's) (two sections per assistant). There were six recitation sections in the first class with 159 students enrolled, and eight recitation sections in the second class with 266 students enrolled. As in experiment one, there were three experimental groups in the study: a learner-generated expert system group, an instructor-provided expert system group, and a control group. Four recitation sections were randomly assigned to the control group, two from each class. The remaining four sections in the first class formed the instructor-provided group, and the six sections from the second class formed the learner-generated group. The learner-generated group was further broken down into three experimental groups (two recitation sections each) representing two different ways to construct the knowledge base (matrix and decision tree) and two ways of inputting the rules into the expert system shell (programming and induction). This created a matrix/programming group, matrix/induction group, and a decision tree/programming group. It was not possible to have a decision tree/induction group, because the induction function in VP-Expert was only available from the matrix building construction strategy. We were also interested in determining whether there were any differences among these groups based on the thinking styles.
23 The restricted randomization to groups was necessitated by practical considerations of the study. Neither the course instructor nor the TA's were informed as to the exact nature of the treatments. The instructor, of course, knew that an experiment was being performed involving a control group and two treatments -- one using an instructor-provided expert system and the other creating one. Students in the first class -- assigned by recitation sections to control and instructor-provided groups -- did not know there was a third experimental group. It is possible (perhaps even likely) that there was some discussion within the first class about the experiment, but only relating to controls and instructor-provided expert systems. It is highly unlikely that there was any interaction between students in the first class and the second class, because the classes were separated in time (by three hours) and in location. Similarly, it is possible that there was some talk within the second class about the experiment, but only relating to controls and learner-generated expert systems. It is hard to imagine that the two treatment groups were aware of one another. Three instructors from the Instructional Systems Program who were knowledgeable about expert systems provided instruction on expert systems in the recitation sections with the TA's absent.
Procedures
24 The students in all three treatments attended an introductory one-hour lecture on the use and development of expert systems in society and the effect these systems have on their lives. This lecture further elaborated on the process of creating an expert system. While differing by type, students in all three groups were given an equal number of special homework assignments and a common final project containing 30 problems.
Control Group: Students in the control group solved ``paper-based'' problems on three assignments and on the final assignment, as they normally would apart from the study.
Instructor-Provided Group: The students in this treatment received instruction on the use of IBM PC's in student labs on campus. They were taught how to access the expert system software from the network. These students received additional instruction on the use of VP-Expert, developed by Sawyer (1987), as a tool to solve problems presented within the framework of an expert system. The subjects practiced the use of the expert system with non-statistical examples provided by the software developer. At the end of the first hour, the students were given an assignment using the expert system to do outside of class time. This homework assignment was collected after one week, graded, and returned to the students. Later in the semester, the students received additional information on the use of the instructor-provided expert system and were given instructions on how to use it to complete their last assignment. This assignment contained 30 problems in which a test of an hypothesis was to be done. There were three problems involving the use of each of ten different test statistics. Each student was to use the instructor-provided expert system outside of class time to determine the best test statistic to use. This homework set was collected on the last day of class.
Learner-Generated Group: The students in the learner-generated treatment also received instruction on the use of the IBM PC's in the student labs on campus. They were taught how to access the expert system software from the network. The students then received instruction on the development of a paper-based knowledge base using one of two techniques -- decision tree or matrix. This was followed later by training on the construction of the rules using the expert system construction shell (VP-Expert), again using one of two techniques -- programming or induction. As a homework assignment, the students were asked to construct a simple knowledge base to solve a simple statistical problem -- that of selecting which type of graphical or numerical technique should be used to describe given data sets. When this was done, students met again in a lab to work on the completion of their expert systems. Additional help sessions were provided for those students having difficulty using the expert system construction tools. Subsequently, students were given the last problem set. These subjects were not required to solve any of the problems in this problem set. The problems were categorized and labeled by the correct test statistic to use in each of ten testing problem categories. These examples were intended to be used as exemplars and as a self-test upon completing the expert system. Each student was, in effect, recreating the instructor-provided expert system used in one of the other two treatments. The construction began with each student's completing a paper-based knowledge base using the methods specific to their training and treatment. After completing the knowledge base, the students were to input the rules into the computer to create a fully functional expert system using the tools and methods they had learned. Help sessions were provided after class to assist students in the technological aspects of the development of the expert system.
Dependent Measures
25 There were three sets of responses available: (a) four in-class tests, each graded on a 100-point scale, (b) the final exam graded on a 200-point scale, and (c) a subset of nine questions on the final exam that were similar to the 30 questions on the last homework assignment. These were each graded as correct (one point) or incorrect (no point). Data are presented here only for those students who gave signed consent. Test 1 covered descriptive statistics, the normal distribution, normal probability calculations, and some regression. Test 2 covered correlation and regression, design of experiments and sampling, basic probability concepts, random variables, and probability distributions. Test 3 covered sampling distributions, the Central Limit Theorem, and statistical inference for one population mean. Test 4 covered statistical inference for one and two-sample problems about means and proportions, and chi-square tests. The final exam was comprehensive and included nine problems in which the students only had to identify which test statistic to use.
Subjects
26 In the two classes, there were 425 students -- 115 in the control group, 116 in the instructor-provided expert system group, and 194 in the learner-generated group; human subjects approval consent forms were obtained from 336 students. Because of missing values for data, 306 cases (or 91.1%) were used in the subsequent analyses -- 86, 70, and 150 (74.8%, 60.3%, 77.3%) of the enrolled students in the respective groups. Thus, the highest percentage of students included in the analyses came from the learner-generated expert system group, unlike Experiment 1 where the corresponding participation rate was much lower. A comparison of the performance of the students who participated versus those who did not (but not adjusted for grade point average) showed that there was a statistically significant difference on all four tests and the final exam, but no treatment by participation interaction effect.
Results
27 Data were analyzed to determine if there were any differences among the three learner-generated groups, the instructor-provided group, and the control group. Ability differences were controlled by using grade point average as a covariate. Follow-up tests were performed only for those main effects that were significant at p <.10. As can be seen in Figure 3 comparing least-squares means, there was very little difference among the five treatment groups on Test 1 and Test 2. Differences between the control group and the groups receiving expert system training widened on the last two tests in favor of the expert system groups, with significant differences among the groups appearing at Test 4 (p=".058)." Follow-up tests revealed significant differences at p < .05 between the control group and all the other treatments. Another interesting difference was found for the decision-making items (p=".073)." Results of the follow-up tests showed a significantly higher performance (p < .05) by the instructor-provided and control groups over the two matrix groups. There was no difference between the two matrix groups and the decision tree/programmed rules group. There was no interaction between the overall treatments and serialist/holist learning styles.
Figure 3. Exam Scores by Treatment by Test Sequence
28 These results were not unexpected. The expert system training was going on periodically during the semester; hence, any possible effects were not expected to appear until near the end of the course. Nevertheless, the results were consistent with our prior predictions, because the training that students were receiving was thought to be beneficial to the learning process. The results on the final exam and the subtest were not initially expected, however. The pattern that had developed on the tests changed, with the control group and instructor-provided groups obtaining higher averages on the final exam and subtest than the learner-generated groups. The explanation for this outcome may lie in the following problem with the study. The last assignment, in which students were to determine which test statistics were appropriate to use in testing problems, was not handed out until near the end of the 13th week of a 15-week semester. Students in the learner-generated group were under severe end-of-the-semester time pressure to complete the task. Several students had difficulty with syntax errors using the expert system shell and spent an unanticipated large amount of time working on creating the expert system to the point where they could demonstrate that it was correct. In fact, some students gave up because of commitments to other courses. This was not a problem with the instructor-provided or control groups.
29 Data were also analyzed to determine if either of the strategies for constructing the paper version of the knowledge base had a greater effect on learning, or if there was a significant interaction with thinking style by examining this effect on the six dependent measures (four tests, final exam, and the subset of nine questions; see paragraph 25 above). One main effect for treatment on Test 2 (p = .039) was found. In this case, those who constructed a decision tree performed better (mean = 85.74) than those who created a matrix (mean = 81.45). No interactions or differences on the other exams were found.
30 A second area of interest regarding the learner-generated treatment was a comparison of the strategies students used to construct the rules for inputting the knowledge base into the computer. Programming the rules requires careful attention to the details of the syntax compared to the induction method. Of special interest was a significant interaction found between strategy and thinking style for the decision-making items -- those items that matched the thinking required for the creation of the expert system (F(2,99) = 3.42, p = .037). Figure 4 shows a disordinal interaction (i.e., an interaction with both positive and negative effects) most effectively. The most striking difference is evident for the serialist learners for whom the sequential programming rule construction strategy was most effective, and the matrix/rule induction strategy dampened learning dramatically. The opposite effect, although not as striking, was found for the holists, who performed better using the induction strategy. For versatile learners, there was virtually no difference.
Figure 4. Mean Scores on the Decision Making Items by Thinking Style
31 These results matched our a priori predictions for rule construction strategy, but not for knowledge construction strategy. Serialists, as defined by Ford (1985), focus on procedures that let the overall picture emerge. Holists, on the other hand, have been described as building broad descriptions into which details will be fit. Versatile learners are able to learn using either approach. It was expected that the matrix knowledge-construction strategy would match the holist style, because the matrix is constructed from a broad framework into which details are filled. The decision tree requires the learner to start with one question that leads to further branched items (top-down) or starts with the solutions and generates unique questions that delineate among solutions to more general ones (bottom-up). This requires a more sequential thinking and construction strategy. In fact, only for Test 2 covering correlation and regression, design of experiments and sampling, basic probability concepts, random variables, and probability distributions was the decision tree seen to be a significantly better strategy -- with no strategy by thinking interaction. One explanation could be that holists use a bottom-up strategy rather than a top-down strategy for creating decision trees, accommodating their more holistic perspective of the problem. This is purely conjecture, as we have collected no data in this regard. We consider it to be an important question to investigate in future research.
32 The disordinal interaction found for the rule construction strategy did support our a priori hypotheses. It seems that the sequential and detailed nature of programming the rules matched the style of serialists, while the induction method matched the style of holists. To induce the rules, the learner typed a matrix into the expert system shell, and the rules and programming were automatically generated by selecting two commands from a menu. It may be that not creating the logic behind the rules had a detrimental effect on serialist learners.
33 Previous results (Grabowski and Harkness 1995) have shown that serialist learners perform significantly better than holist learners on statistics exams. In light of these results, our finding is encouraging. By carefully considering the strengths in the thinking processes of serialist and holist learners, we may be able to accommodate some of those differences in thinking styles.
34 From these two studies, we conclude that the generative nature of creating or using an expert system results in greater learning gains than not using an expert system. When learners were asked to create their own knowledge base, they were forced to put onto paper their understanding of the statistical concepts and how they interrelate. To generate this knowledge base, students need to have a firm grasp of both the concepts and the interrelationship of the underlying concepts with one another to form decisions. An unexpected benefit was that student misconceptions about their statistical understanding were revealed by the development of this knowledge base. The details of this finding are reported separately by Grabowski and Harkness (1996).
35 In this regard, we found, however, that a critical step was missing in our study -- one that appeared to be important to learning. That was to provide feedback to the students on the appropriateness of the assumptions they made about the relationships among concepts prior to the conclusion of the course. We feel that if students had been given this feedback, the learning gains found by Test 4 would have extended into the final exam. The 30-problem homework sets were to function as a means for self-guided feedback; however, the end-of-the semester time pressure did not allow enough time for all the components of creating the expert system to come together as they should have. Developing an understanding of all of the concepts was also evolutionary, with understanding coming together for the students at the end as well.
36 Once the subjects became heavily involved in constructing the rules on the computer, intense frustration and cognitive effort was expended on the technology rather than on statistics. While students were not surveyed in this regard, informal observations of subjects in the labs toward the end of the semester and additional notes attached to some of the final projects corroborates this speculation.
37 Given both of these problems, perhaps a better strategy would be to require smaller expert systems due throughout the semester to enable the students to get corrective feedback prior to the exams. This would capture the essence of the benefits of creating expert systems without much of the undue end-of-the semester stress from trying to create the knowledge base, program it, and test it out all at once.
38 There are several possible explanations of the benefits of providing an expert system to the students. First, the students were required to think about various statistical concepts and to answer a series of questions about different scenarios to get advice on which statistical procedure to use. They were not simply told which procedure goes with each type of problem. They were also engaged in the same type of thinking throughout the semester that was required on the exam. Providing the subjects with an expert system created by their instructor was like providing them with a model of his thinking for making statistical procedure decisions. By running his expert system, subjects learned the logic they would need when answering the same type of questions.
39 Instructors can implement these recommendations and capitalize on the positive effects of computers as thinking tools, while minimizing the technological problems, by offering what could be called integrated courses. Under this model, two courses, one in a content area such as statistics and the other in the technological aspects of the computer as a thinking tool, could be offered to the same students in the same semester. The course assignments would be drawn from the content area and would require students to use the computer to help them think and draw conclusions about what they were learning. In this way, students would learn three things in context -- the course content, how to learn with a computer, and how to execute that learning on a computer -- without trying to cram all three into one time slot that is already content-intensive.
The authors would like to acknowledge substantial assistance from Mark Davidson and Gary Hettinger, doctoral candidates in the Instructional Systems Program at Penn State. Preliminary results of this study were presented at the 1995 Joint Statistical Meetings in Orlando, Florida.
Appendix A. Expert System Rules for the
Instructor-Provided Treatment: Final Assignment
[Comments in square brackets have been added for clarification; they do not appear in the actual expert system. This section contains opening statements about the expert system and its intended use.]
RUNTIME; ENDOFF; ACTIONS WOPEN 1,2,6,15,66,7 ACTIVE 1 DISPLAY '' S T A T I S T I C S E X P E R T A D V I S O R This system was designed to provide expert assistance in the selection of a statistical test for a given problem. This system was designed specifically for use by the students of Dr. Harkness' Statistics 200 Course. Press any key to begin the consultation.~'' CLS[The following are _action statements_ that tell the computer what to do. For each of the RULES below, a (variable) number of questions are to be answered, with a (variable) number of CHOICES. A list of these questions and the choices is given immediately after RULE 11. For example, the first question (always) is ASK Problem_Type: ``What type of response variable do you have?'' The CHOICES are: Problem_Type: Proportions, Means. Depending on the choice, further questions are asked, with corresponding choices for answers.]
FIND Test
WOPEN 2,13,13,9,50,0
WOPEN 3,14,15,7,46,4
ACTIVE 3
DISPLAY'' The best choice for a statistical test is {Test}.
Press any key to conclude this consultation.~'';
RULE 0
IF Problem_Type = Proportions AND
Number_of_Samples = 1 AND
Sample_Size = Small
THEN Test = there_is_no_solution;
RULE 1
IF Problem_Type = Proportions AND
Number_of_Samples = 1 AND
Sample_Size = Large
THEN Test = the_Z-test_for_a_single_proportion_P;
RULE 2
IF Problem_Type = Proportions AND
Number_of_Samples = 2 AND
Alternative_2 = No
THEN Test = the_Z-test_about_two_proportions;
RULE 3
IF Problem_Type = Proportions AND
Number_of_Samples = 2 AND
Alternative_2 = Yes
THEN Test = the_Chi-squared-test_for_2_sides;
RULE 4
IF Problem_Type = Proportions AND
Number_of_Samples = 3_or_more
THEN Test = the_Chi-squared-test_for_homogeneity;
RULE 5
IF Problem_Type = Means AND
Number_of_Samples = 1 AND
Variance = Yes
THEN Test = the_Z-test_about_mu;
RULE 6
IF Problem_Type = Means AND
Number_of_Samples = 1 AND
Variance = No
THEN Test = the_T-test_about_mu;
RULE 7
IF Problem_Type = Means AND
Number_of_Samples = 2 AND
Sample_Paired = Yes
THEN Test = the_T-test_about_mu;
RULE 8
IF Problem_Type = Proportions AND
Number_of_Samples = 2 AND
Sample_Paired = Yes
THEN Test = the_z_test_about_proportions;
RULE 9
IF Problem_Type = Means AND
Number_of_Samples = 2 AND
Variance = Yes AND
Sample_Paired = No
THEN Test = a_2_sample_Z-test;
RULE 10
IF Problem_Type = Means AND
Number_of_Samples = 2 AND
Variance = No AND
Sample_Paired = No
THEN Test = a_2_sample_T-test;
RULE 11
IF Problem_Type = Means AND
Number_of_Samples = 3_or_more
THEN Test = _use_analysis_of_variance;
ASK Problem_Type: ``What type of response variable do you have?
If the response variable is categorical, the problem is _proportions_
If the response variable is quantitative, the problem is _means_.'';
CHOICES Problem_Type: Proportions, Means;
ASK Number_of_Samples: ``How many samples?
simple random sample, use one.
stratified random sample, use the number of strata.
experimental data, use the number of treatments.'';
CHOICES Number_of_Samples: 1,2,3_or_more;
ASK Sample_Size: ``How large is the sample size (n)?'';
CHOICES Sample_Size: Small,Large;
ASK Alternative_2: ``Do you have a two sided
alternative?'';
CHOICES Alternative_2: Yes,No;
ASK Variance: ``Is the variance known?'';
CHOICES Variance: Yes,No;
ASK Sample_Paired: ``Are the data paired?
Is the design a paired comparison (or randomized block)?
If so, the samples are paired.'';
CHOICES Sample_Paired: Yes,No;
Appendix B. Sample Problems from the Final Homework
Assignment
I. Question for which a z-test about a single proportion p is the answer:
In order to determine whether a pro-choice leader's claim that 70% of all women support a woman's right to have an abortion is true or not, a simple random sample of 1200 adult women was obtained. It was found that 64% of these women believe that a woman does have this right. Is there sufficient evidence to reject the pro-choice leader's claim at the alpha = .05 level of significance?
II. Question for which the z-test about two proportions p_1 and p_2 is the right answer:
After a frost, the owner of two orange groves randomly sampled 100 trees from each grove to assess the proportion of trees in each grove that had been damaged. The sample from the first grove (which is located at a slightly higher elevation than the second grove) contained 38 damaged trees, while the second grove had 22 damaged trees. Is there sufficient evidence to reject the hypothesis that the proportion of trees damaged in the two groves is the same versus the alternative that the proportion is higher in the first grove? Test using alpha = .05.
III. Question for which either the z-test or the chi-square test about two proportions is the right answer:
A public and a private university are located in the same city. For the private university, 1046 alumni were surveyed, and 653 (or 62.4%) said that they had attended at least one class reunion. For the public university, 791 of 1327 sampled alumni (or 59.6%) claimed they had attended a class reunion. Test, at the alpha = .05 level, whether the proportion of alumni who have attended reunions from the two universities is the same versus the alternative that they are not equal.
IV. Question for which the chi-square test of homogeneity of proportions is the right answer:
The grade distributions in two Statistics 200 classes were obtained; the results are given below:
Grade
A B C D F Total
1 30 95 125 60 20 330
Class
2 24 66 105 35 20 250
Total 54 161 230 95 40 580
Is there sufficient evidence to conclude that the grade distributions in the two classes are different? Test using alpha = .05.
V. Question for which the right answer is a z-test about a population mean (Population standard deviation is assumed known):
The average IQ on the Stanford-Binet IQ test is 100, with a standard deviation of 16. An epidemiologist wishes to see if the average IQ of Cuban immigrants over the past five years is the same as among all people (100) or whether it is lower (because of their being in a lower socio-economic class on the average). A simple random sample of size 64 yielded an average IQ of 98.5. Test the hypothesis that the immigrants' average IQ is 100 versus the alternative that it is lower, using alpha = .05.
VI. Question for which the right answer is a t-test about a population mean (Population standard deviation is not known):
Your new car has an EPA rating of 26.0 miles per gallon. You wonder if this is right for your car. You record the mpg for five ``fill-ups'' and obtain the following results: 21.4, 25.0, 26.8, 23.6, and 24.0. For this sample, the average is 24.16 mpg and the standard deviation is 1.98 mpg. Test the hypothesis that the average for your car is 26.0 versus the alternative that it is less than 26.0; use alpha = .10.
VII. Question for which the t-test for paired comparisons is the right answer (Samples are paired):
Six junior executives were sent to a class to improve their verbal skills. To test the quality of the program, the executives were tested before and after taking the class, with the following results:
Name of Executive
Levin Baker Craft Denny Lonny Harry
Before 18 30 8 10 12 12
Score
After 30 70 20 4 10 20
Do these results indicate a significant improvement in verbal skills at the .01 significance level?
VIII. Question for which the right answer is a 2-sample t-test (independent groups):
To determine if a new gasoline additive improves the mileage performance of gasoline, seven test runs were conducted with the additive, and six runs were made without it. The test results appear below. Is there sufficient evidence at the ..05 level to conclude that the additive increases gasoline mileage?
With additive: 32.6 30.1 29.8 34.6 33.5 29.6 33.8 Without additive: 31.3 29.7 29.1 30.3 30.9 29.9
IX. Question for which the right answer is a test about the slope of a regression line:
Is there a relationship between the number of votes received by candidates for public office and the amount spent on their campaigns? The following table gives sample information on four candidates in a recent election:
Candidate Amount spent Votes received Weber $30000 14000 Tate $40000 7000 Spencer $20000 5000 Lopez $50000 12000
Test to see if there is a significant linear relationship between amount spent and the number of votes received.
X. Question for which the right answer is a z-test about a proportion in paired samples (McNemar test):
A study was conducted to see if the `degree of satisfaction' in marriages is the same for husbands and wives. Three hundred married couples were asked to evaluate their marital satisfaction by giving a yes or no response to the question ``Are you happy with your marriage?'' The results of the study were as follows:
Wife's Response
Yes No Total
Yes 105 75 180
Husband's No 55 65 120
Response
Total 160 140 300
At the alpha = .05 level, test the hypothesis that in those marriages where there is disagreement about marital satisfaction, the husband's rating is higher than the wife's in 50%, and the wife's rating is higher than the husband's in 50%.
Andrews, F. M., Klem, L., Davison, T., O'Malley, P., and Rodgers, W. (1981), A Guide for Selecting Statistical Techniques for Analyzing Social Science Data (2nd ed.), Ann Arbor, MI: Institute for Social Research, University of Michigan.
Ford, N. (1985), "Learning Style and Strategies of Postgraduate Students," British Journal of Educational Technology, 16(1), 65-79.
Grabinger, R. S., Wilson, B. W. and Jonassen, D. H. (1990), Building Expert Systems in Training and Education, New York: Praeger.
Grabowski, B. L., and Harkness, W. L. (1995), "Expert Systems as an Instructional Strategy in Statistics: A Case Study," in Proceedings of the Section on Statistical Education, American Statistical Association, pp. 90-94.
----- (1996), "Using Expert Systems to Detect Student Misconceptions in Statistics," paper presented at the 1996 Joint Statistical Meetings, to appear in Proceedings of the Section on Statistical Education, American Statistical Association.
Jonassen, D. H. (1996), Computers in the Classroom: Mindtools for Critical Thinking, Englewood Cliffs, NJ: Prentice Hall.
Knox-Quinn, C. (1992), "Student Construction of Expert Systems in the Classroom," paper presented at the annual conference of the Association for Educational Communications and Technology.
Lai, K. W. (1989), "Acquiring Expertise and Cognitive Skills in the Process of Constructing an Expert System: A Preliminary Study," paper presented at the annual conference of the American Educational Research Association, San Francisco, CA.
Lippert, R. C. (1988), "Teaching Problem Solving in Mathematics and Science With Expert Systems," School Science and Mathematics Journal, 87(6), 477-493.
----- (1988), "An Expert System to Teach Problem Solving," Tech Trends, 33, 22-26.
Olson, D. R. (1985), "Computers as Tools of the Intellect," Educational Researcher, 6-8.
Pea, R. D. (1985), "Beyond Amplification: Using the Computer to Reorganize Mental Functioning," Educational Psychologist, 20(4), 167-182.
Salomon, G., Perkins, D. N., and Globerson, T. (1991), "Partners in Cognition: Extending Human Intelligence With Intelligent Technologies," Educational Researcher, 20(3), 2-9.
SAS Institute Inc. (1996), JMP, Statistical Discovery Software, Cary, NC: SAS Institute Inc.
Sawyer, B. (1987), VP-Expert: Rule-Based Expert System Development Tool, Orinda, CA: WordTech Systems Inc.
Steinhorst, R. K., and Keeler, C. M. (1995), "Developing Material for Introductory Statistics Courses from a Conceptual, Active Learning Viewpoint," Journal of Statistics Education [Online], 3(3). (http://jse.amstat.org/v3n3/steinhorst.html)
Triola, M. F. (1994), Elementary Statistics (6th ed.), Reading, MA: Addison-Wesley.
Trollip S. R., and Lippert R. C. (1987), "Constructing Knowledge Bases: A Promising Instructional Tool," Journal of Computer Based Instruction, 14, 44-48.
Wideman H. H., and Owston, R. D. (1988), "Student Development of an Expert System: A Case Study," Journal of Computer Based Instruction, 15, 88-94.
Barbara L. Grabowski
310E Keller Building
The Pennsylvania State University
University Park, PA 16802
William L. Harkness
310 Classroom Building
The Pennsylvania State University
University Park, PA 16802
 Figure 2 (9.3K GIF)
Figure 2 (9.3K GIF)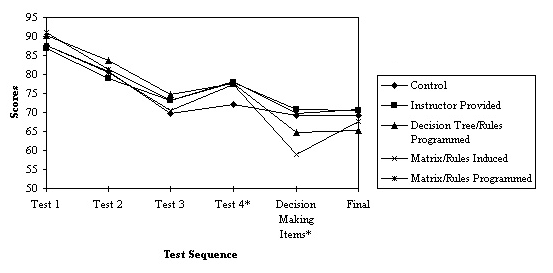 Figure 3 (11.6K GIF)
Figure 3 (11.6K GIF)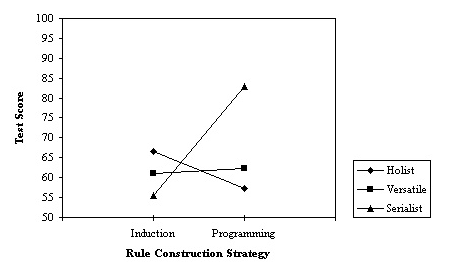 Figure 4 (8.1K GIF)
Figure 4 (8.1K GIF)