Information Exploration and Retrieval:
A Brief Introduction to the Internet
North Carolina State University
Department of Statistics
Compiled from several network sources by
Paul Marsh
Tim Arnold
Table of Contents
- Introduction
- Connecting to the Internet
- Electronic Mailing Lists (Discussion Groups)
- File Transfers (FTP)
- Finding Interesting Files: Archie and Wais
- Connecting to Other Internet Hosts
- Usenet
- Gopher and Related Tools
- WWW
- Glossary
- A: Books
- B:Ftp-able Documents
Bibliography
Introduction
The Internet - what is it? We certainly see and hear allusions to this vague and vast term seemingly daily. Is it going to be the basis for the "information highway"? Perhaps. Many basic information exploration and retrieval tools are already available to virtually all computer literates.
The Internet is broad and vast not only in geographic area but also in the tools available to users. New users joining the Internet community usually have the same questions: How do I get connected? Once I am connected, what can I do?
This manual attempts to answer several such questions. Beginners should scan the whole document first to get a conceptualization of the exciting power of the Internet. Also, an overall view of the Internet is needed since many of the information browsing tools work jointly to perform a specific task. After that? Buckle up and try it!!
Loosely defined, a network is a set of computers using the same protocol to communicate among themselves. In a general sense, a protocol is the set of rules used in communicating.
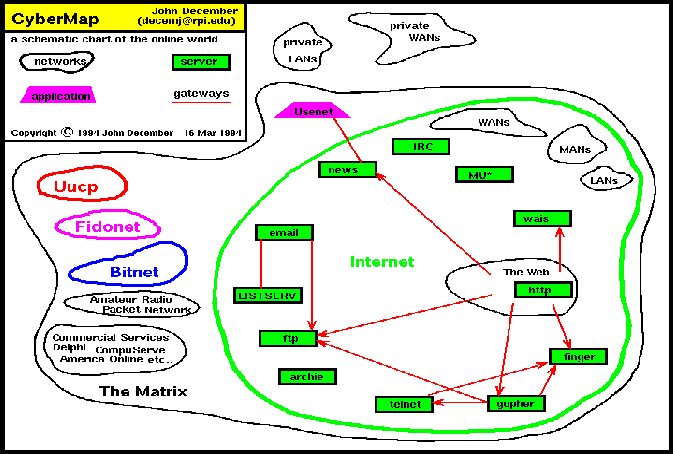 Cybermap
(14K gif)
Cybermap
(14K gif)
The Internet is a large collection of networks, all of which run the same protocol (TCP/IP). The Internet started with the ARPANET, but now includes such networks as NSFNET and NYSERnet. There are other major networks, such as BITNET and DECnet, that are not based on the same protocol and are thus not really part of the Internet. However, users on these networks still may have some access to the Internet: Gateways are established to allow for inter-network communications. Gateways are computers that physically link the various networks and translate the protocols among them. Gateways are usually not noticeable the people who use them.
Once on the Internet, you have access to
- all the resources on your own Internet host,
- on any other Internet host on which you have an account, and
- on any other Internet host that offers publicly accessible information.
The Internet gives you the ability to move information between these hosts via file transfers (generically known as ftp-ing). Once you are logged into one host, you can use the Internet to open a connection to another, login, and use its services interactively (this is known as telnet). In addition, you can send electronic mail to users at any Internet site and to users on many non-Internet sites.
There are various other services you can use. For example, some hosts provide access to specialized databases or to archives of information. The Internet Resource Guide provides information regarding some of these sites. The guide is published by the NSF Network Service Center (NNSC) and is continuously updated.
The files which make up the Guide
may be obtained through electronic
mail by sending a message to mailserv@ds.internic.net.
To retrieve
individual files, include the FILE command in the message body. Some
examples are:
file /ftp/resource-guide/overview
file /ftp/resource-guide/chapter.1/section1-14.ps
The LS (or DIR) command may also be used to get a directory listing of
the Guide. Use the following command in the message body:
ls /ftp/resource-guide.
The Resource Guide is also available via anonymous FTP to ds.internic.net. The /resource-guide/overview file is a good place to start.
Connecting to the Internet
Military, governmental, and educational institutions usually have full access to the network. Recently, commercial vendors have begun offering connections for companies and persons not affiliated with such organizations.
If you just have a personal computer and a modem, you can obtain a list of internet access providers to whom you may connect via modem. The list is called PDIAL and may be retrieved by sending e-mail to:
info-deli-server@pdial.com with this message:Send PDIAL
There is also a web site with a PDIAL
list.
For more introductory information, see the
PDIAL FAQ's (Frequently Asked Questions.
O'Reilly and Associates has a mail server that provides a list of Internet Access providers who offer dedicated line connections (a direct link from your computer to the Internet).
Send e-mail to: dlist@ora.com with an empty message body.Electronic Mail
By using electronic mail (abbreviated as e-mail), you are able to send messages or entire files at your convenience to anyone, anywhere on the network. Just as with postal mail, the receiver need not be present to receive the message and may in turn read it at his/her convenience. One great difference between postal and electronic mail is that messages delivered via the latter often arrive within minutes, regardless of the distance that must be travelled.
To send a message, you must know the addresses of persons to whom you wish to send e-mail. E-mail addresses can be quite complex. There are a number of address directories on the Internet; however, all of them are far from complete. Generally, it is still necessary to ask the person for his or her e-mail address.
E-mail on the Internet uses addresses of the form user@location. user is generally the account name of the mail recipient. location identifies the name and place of the computer housing the recipient's account. The '@' merely acts as a separator between these two identifiers.
Much information regarding who sent the electronic mail can be gleaned from breaking down location into its one or more components. The parts of location are separated by '.' (periods). The rightmost part is always the domain. Networks outside the United States are identified by two-letter codes: CA for Canada, ES for Spain, TW for Taiwan, UK for the United Kingdom, and so forth. Generally speaking, networks within the United States are still identified by the nature of their owners: COM for commercial companies, EDU for educational institutions, GOV for government facilities, MIL for military sites, NET for network support groups, and ORG for other miscellaneous organizations. It is becoming more common, though, to see the .US domain in addresses for institutions in the United States.
The next rightmost part of location is the subdomain. The subdomain usually identifies the organization (company, military base, university) where the sender is located. Sometimes a second subdomain is added to distinguish different areas of the same organization.
For more information: How to Find People's Email Addresses
You see a strange looking address?
There are several networks accessible via e-mail from the Internet, but many of these networks do not use the same addressing conventions the Internet does. Often you must route e-mail to these networks through specific gateways as well, thus further complicating the address. Messages that go through several gateways often include a "bang" (!), a percent sign (%), or double colons (::), suffixed to the person's user id.
Additional reading on electronic mail:
Frey, D. & Adams, R. (1990) A Directory of electronic mail addressing and networks. Sabastopol, CA: O'Reilly Associates.Electronic Mailing Lists (Discussion Groups)
A mailing list is really nothing more than a nickname for multiple users: Electronic mail directed to the list is sent to all those users. Mailing lists are usually created to discuss specific topics. Anybody interested in that topic, may (usually) join that list. Some mailing lists have membership restrictions, others have message content restrictions, and still others are moderated.
There is a "list-of-lists" file available on the host sri.com that lists most of the major mailing lists, describes their primary topics, and explains how to subscribe to them. The file is available for anonymous ftp in the netinfo directory under the name interest-groups (that is, the path is: netinfo/interest-groups). It can also be obtained via electronic mail.
Send a message to mail-server@sri.com with the body of the message reading,Send interest-groups
(or for a directory of files:
Send directory)
and the file (a large one!) will be returned in moderate size pieces via electronic mail.
Mailing lists are sometimes called LISTSERV or as electronic discussion groups. LISTSERV stands for "list server". Originally, LISTSERV was a mailing-list programmed to make group communication easier. Similar programs now exist on the Internet, and although they are not technically the same, most people speak of "listserv lists" as a generic term.
People with a common interest (e.g. network protocols, issues related to handicapped people in education, system administration problems) may join or subscribe (although there is no exchange of money) to a list. Merely send the following e-mail message to the host computer (it "owns" the list):
subscribe list-name Your Full Name
where list-name is the name of the desired electronic discussion group.
Messages sent to the list are automatically distributed to all subscribers. Any member can reply to the message and this reply will in turn be distributed to every one else in the group. The electronic conversation continues as long as anyone is interested in discussing the subject at hand. Then someone else raises a new issue and the process begins anew.
File Transfers (FTP)
Another tool available to Internet users is electronic file transfer via a facility generically know as FTP (which stands for file transfer protocol). Network software packages generally include such software in the distribution. It should be noted, however, that only the "client" side of the software is generally available. That is, the software to contact a host computer and subsequently send or receive files. This is usually sufficient for most users. Your network software documentation should outline the commands available to you within the ftp facility. If you wish to set up a host computer for other Internet users to contact for file transfers, you will have to locate the "server" side of an FTP software package.
Generic FTP allows authorized users to contact a host machine and perform file transfers. An authorized user generally already has an account on the host machine.
Anonymous FTP allows guest users to have restricted access to many information archives on the network. To allow this wider class of Internet users to perform file transfers, system administrators authorize a generic anonymous userid. Users merely enter that name when prompted for user-id and are allowed to access certain disk directories on the host computer. At the password prompt, reply with your electronic mail address.
To access an anonymous ftp site you must know the address of the site. For example, nic.ddn.mil, is the address of the Network Information Center of the Dept. of Defense Network. It is generally a good idea to list the contents of possible directories before transferring a file via anonymous ftp. Look for files named readme or index first. Names and locations of directories and files may change over time. By checking your listing of possible directories and files, you increase your chances of successfully transferring a file.
The procedure for accessing an anonymous ftp site follows:- type: ftp nic.ddn.mil
- Connected to nic.ddn.mil
- 220 NIC.DDN.MIL FTP Server Process at Tue 30-Jul-91
- Name (nic.ddn.mil:msmith) : anonymous
- Password (nic.ddn.mil:anonymous) :---------
- 331 ANONYMOUS user ok, send real ident as password.
- 230 User ANONYMOUS logged in at Tue 30-Jul-91
- ftp>
- at the Unix prompt, user ftp's to nic.ddn.mil
- user is connected to ftp site
- site notes the time of user login
- user login as anonymous
- user types address (e.g., bjp@sura.net) which does not appear
- system acknowledges user login and notes time
- ftp prompt
To transfer a file, you may have to change directories to the directory that your file is located in. It is a good idea to list the contents of the directory before attempting to transfer a file.
Unix Commands for Retrieving Files
ls (or dir) command lists the contents of the active
directory.cd directory name command enables the user to change directories (move
up or down the hierarchy)cd .. command allows the user to return
to the previous directory.To transfer a document:
get filename
To view the document while still connected to the ftp site:
get filename |more
For more information: FTP FAQ List
Finding Interesting Files: Archie and Wais
There are literally thousands of interesting programs, datasets, and documents freely available on the Internet. Two tools to aid in the location of such interesting information are archie and wais.
Archie
The archie service is a collection of resource discovery tools that together provide an electronic directory service for locating information in an Internet environment. Originally created to track the contents of anonymous ftp archive sites, the archie service is now being expanded to include a variety of other online directories and resource listings.
Users can access an archie server either through interactive sessions (provided they have a direct Internet connection) or through queries sent via electronic mail messages (provided they can at least gateway electronic mail messages onto the Internet).
Interactive access to archie may be through a conventional telnet session to a machine running an archie server or through an archie client.
The archie server automatically updates the listing information from each site about once a month, ensuring users that the information they receive is reasonably timely.
Users with direct Internet connectivity can try out an interactive archie server using the basic "telnet" command (available at most sites). To try this, telnet to the host archie.mcgill.ca and login as user archie (no password is needed). A banner message giving latest developments and information on the archie project will be displayed and then the command prompt will appear. First-time users should try the help command to get started.
Users with only email connectivity to the Internet should send a message to archie@archie.mcgill.ca, with the single word help in either the subject line or body of the message. You should receive back an email message explaining how to use the email archie server, along with details of an email based ftp server operated by Digital Equipment Corporation that will perform ftp transfers through email requests.
Documentation for the archie system is still limited, but what there is is also available for anonymous ftp from the same host (archie.mcgill.ca) under the directory bunyip-docs/archie.whatis.
Wais
The second information tool, WAIS (Wide Area Information Servers), not only locates files based upon their names (as archie does), but also by knowing what is in the files. Wide Area Information Servers, pronounced "wayz," allow you to search through archives of files for which indexes exist. The program searches the text itself, not just the file name, for your desired term. The results are then presented in a weighted list, with those judged "best" listed first, and others listed in decreasing order of relevance. You may then select items you want to see in full, and the system will retrieve them for you.
The major drawback is that WAIS can search only those documents that have been specially formatted to make them compatible to the WAIS software. Unfortunately, this includes only a small percentage of the files available on the Internet.
How Can I Find Out More About Wais?
There is a mailing list that has weekly postings on progress and new releases; to subscribe send an email note to wais-discussion-request@think.comwith the word 'help' in the body of the message.For more information: WAIS FAQ's
Connecting to Other Internet Hosts-Telnet
A basic Internet service is the provision of interactive login to a remote host. Telnet is both a protocol and a program that enables you to do so. It is the standard TCP/IP remote login protocol. You must know the Internet (IP) address of the remote host computer before you can initiate a session with telnet. Many remote hosts require you to have an account to log in (You must have a user id and a password). However, some remote hosts do not require that users have accounts (as in the archie example above). Users can log in with a general user id such as info or guest (or some other word that is published in guides to the Internet). Passwords are usually not required.
UseNet
UseNet is the formal name, and Netnews a common informal name, for a distributed computer information service that some hosts on the Internet use. UseNet handles only newsgroups and not mail. It uses a variety of underlying networks for transport. Netnews can be a valuable tool to economically transport traffic that would otherwise be sent via mail. UseNet has no central administration.
Hundreds of forums, called newsgroups, can be found on UseNet. They differ from LISTSERV mailing lists in that each article is posted only once, for all to read and reply to, rather than having separate messages sent individually to each reader. It functions like an electronic bulletin board.
It should be kept in mind that UseNet is a very different entity from the Internet. The Internet is a wide-ranging network but it is only one of the various networks carrying UseNet traffic.
To help hold Usenet together, various articles are periodically posted in newsgroups in the news hierarchy. It is recommended that new users subscribe to and read the group news.announce.newusers since it will help to become oriented to UseNet and the Internet.
The following sites have sources to the current newsreader software: Site Contact
---- -------
osu-cis postmaster@cis.ohio-state.edu
philabs usenet@philabs.philips.com
pyramid usenet@pyramid.com
rutgers usenet@rutgers.edu
tektronix news@tektronix.tek.com
watmath usenet@watmath.waterloo.edu
uunet info@uunet.uu.net
The archie service can be used to locate ftp archives containing various news software packages.
What is the "FAQ" list?
This list provides answers to "Frequently Asked Questions" that often appear on various USENET newsgroups. The list is posted every four to six weeks to the news.announce.newusers group. It is intended to provide a background for new users learning how to use the news. The FAQ list provides new users with the answers to such questions, helping to keep the newsgroups themselves comparatively free of repetition. Often specific newsgroups will have and frequently post versions of a FAQ list that are specific to their topics. These FAQs are themselves treasures of information on a vast array of topics.
For more information:
A FAQ about FAQ's
News.Newusers.questions
What
is Usenet
Usenet
FAQ
Gopher and Related Tools
Gopher
With the Internet Gopher you can easily access publicly available information stored on many of these connected computers. Gopher combines features of electronic bulletin board services and databases, allowing you to either browse a hierarchy of documents, or search for documents that contain certain words or phrases.
You can use gopher to search thousands of sites and millions of documents without knowing a single Internet address, file name, or locally idiosyncratic command. You just sniff around "Gopher Space" like you would browse your local library, using structured menus to guide you along the way.
Gopher systems are multiplying rapidly, and becoming more sophisticated. And since they all connect to one another, as well as to various WAIS and Archie servers, you can explore virtually any part of the net using a single, relatively simple, interface.
The Internet Gopher software was conceived at the Computer and Information Services department of the University of Minnesota. Software developed at the University of Minnesota is freely distributable for non-commercial purposes. The Internet Gopher works on a number of platforms and operating systems.
Gopher supports a diverse range of data, all of which can be accessed by a simple keystroke or click of the mouse. The most basic information type in gopher is a directory. A directory is simply a list of documents. Directories allow easy browsing of information since items can be organized into specific areas.
There are several different special types of directories also. One special type of directory called a link allows gopher to reference other gopher directories on a different computer. This allows gopher to traverse a hierarchy of information residing on multiple machines across the Internet. These links are transparent: you won't even notice that you're connecting to another machine.
Gopher also provides for a special kind of directory which allows document searching. You can specify any number of keywords to a search item. Only those documents that match the given criteria will show up in the resulting list.
In addition to directories, items can be "documents". Usually documents are plain text files. Other types of documents allow for public telnet connection, "phone book" databases that allow you to search, and multimedia file formats including images, audio and video file formats. Images such as weather maps are available. Audio data, including the presidential debates is available. Movies in Quicktime and MPEG formats are available. Some Gopher servers will allow you to view documents in formats other than plain text. Postscript is one of the most popular formats.
When using Gopher, looking for information located in other continents is as easy as looking for information residing on a computer in the next room.
You may want to follow the paths in Gopher from level to level until you find the data you're looking for (browsing). From the first level, you can choose a topic, which leads to another level, and another, until you finally come to an item that looks interesting.
Alternatively, you may want Gopher to do the work for you by using a search item. For instance, you could select a search item called Search Recipes. A message prompts you to type in the words you're looking for; you type salmon. The server searches the text of a collection of items and lists the ones that have the word salmon in them. You can then examine these items until you find one that contains a recipe that strikes your fancy.
If you merely wish to find interesting Internet materials using gopher, you need only a gopher client program. Most of the software for the Internet Gopher is available on the machine boombox.micro.umn.edu. You may retrieve the software using anonymous FTP. Just look within the /pub/gopher directory for the subdirectory that refers to your specific computer type. Alternatively, if you cannot locate a gopher client, you may telnet to any of the public gopher sites listed below and login using the referenced special user account. Either way, you can be quickly on your way to gopherland!!
Public Gopher Sites
Hostname Login name
consultant.micro.umn.edu gopher
gopher.uiuc.edu gopher
panda.uiowa.edu panda
For more information: Gopher FAQ
Veronica
Closely linked to gopher is veronica (Very Easy Rodent-Oriente d Net-wide Index to Computerized Archives).
Veronica evolved as a solution to the problem of resource discovery in the rapidly expanding gopher world. Veronica offers a keyword search of most gopher server menu titles in the entire gopher web. As archie is to ftp archives, veronica is to gopherspace. A veronica search produces a menu of gopher items, each of which is a direct pointer to a gopher data source. Because veronica is accessed through a gopher client, it is easy to use, and gives access to all types of data supported by the gopher protocol.
If your local gopher server does not already have a link to veronica, use gopher to go to the server at gopher.micro.umn.edu. Choose the menu item "Other Gopher and Information Servers". Choose veronica from that menu.
GopherMail
In addition to Veronica, GopherMail is a gopher client that uses electronic mail to interact with the user. It is pretty clumsy to use, but it works. Messages containing menus and gopher link information are mailed to users in response to their requests. Users reply to these messages and indicate which menu items they want. It lets people use Gopher without requiring them to have an account directly on the Internet, because it communicates through email messages instead of direct "live" network connections. Thanks to the GopherMail program, most of the resources of Gopher are now available to everyone with email-only access to the Internet.
You can get started by sending mail to gophermail@ncc.go.jp with any or no subject and any or no message body. GopherMail will reply by sending you it's main gopher menu. You then use your email program to reply to that message, including it in the text of your reply. Mark which menu options you want to follow-up by putting an X anywhere near the beginning of the line, before the menu numbers for those options.
From there you can just keep repeating the process, sending replies back to gopher with the desired items marked with an X.
World Wide Web (WWW)
As technology continues to develop in the area of information navigation, presentation and retrieval on the Internet, the information servers present on the Internet continue to refine their goals and implementation. Recent months have given rise to three important, interlocking developments on the Internet. These are the World-Wide Web, HyperText Markup Language, and the Mosaic user interface.
The WWW project, started and driven by CERN (the European Laboratory for Particle Physics), seeks to build a distributed hypermedia system. The World-Wide Web is a client/server system, similar to the Gopher information system, for providing integrated text, graphics, sound, and video over the Internet. It has the capability, through the use of HyperText Markup Language (HTML), to link files to one another in a hypertextual structure.
HTML is a specific document definition specified in Standard Generalized Markup Language (SGML). The chief power of HTML comes from its ability to link regions of text and images to another document, document section, sound or image. These links can also offer an interactive search of a set of documents.
To access the web, you run a browser program. The browser reads documents, and can fetch documents from other sources. Information providers set up hypermedia servers from which browsers can get documents.
These browsers can also access files by FTP, gopher and an ever increasing range of other methods. The browsers will also permit searches of documents and databases.
The documents that the browsers display are hypertext documents (text with pointers to other text). The browsers let you deal with the pointers in a transparent way -- select the pointer, and you are presented with the text that is pointed to.
Hypermedia is a superset of hypertext -- it is any medium with pointers to other media. This means that browsers might display not simply text files, but images or sound or animations.
WWW software use URLs to locate information. URL stands for "Uniform Resource Locator". It is a standard for specifying an object on the Internet, such as a file, picture, video clip, or newsgroup.
URLs look like this:file://wuarchive.wustl.edu/mirrors/msdos/graphics/gifkit.zip
file://wuarchive.wustl.edu/mirrors
http://info.cern.ch:80/default.html
news:alt.hypertext
telnet://dra.com
The first part of the URL before the colon, specifies the access method. The part of the URL after the colon is interpreted specific to the access method. In general, two slashes after the colon indicate a machine name.
You have two options to access the world-wide web. Either use a browser that can be telnetted to, or use a browser on your machine.
While WWW, gopher, and Wais all are client-server based, they differ in terms of their model of data. In gopher, data is either a menu, a document, an index or a telnet connection. In WAIS, everything is an index and everything that is returned from the index is a document. In WWW, everything is a (possibly) hypertext document which may be searchable.
In practice, this means that WWW can represent the gopher (a menu is a list of links, a gopher document is a hypertext document without links, searches are the same, telnet sessions are the same) and WAIS (a WAIS index is a searchable page, returning a document with no links) data models as well as providing extra functionality.
Currently accessible through the web:- anything served through gopher
- anything served through WAIS
- anything on an FTP site
- anything on Usenet
- anything accessible through telnet
- anything in hytelnet
- anything in hyper-g
- anything in techinfo
- anything in texinfo
- anything in the form of man pages
- sundry hypertext documents
One of the few limitations of the current networked information systems is that there is no simple way to find out what has changed, what is new, or even what is out there. As a result, a definitive list of the web's contents is impossible at this moment.
For more information: The World Wide Web FAQ
Mosaic (The Web via a mouse-based browser)
Building on the Web's initial structures, NCSA Mosaic uses a client/server model for information distribution. A server sits on a machine at an Internet site answering queries sent by NCSA Mosaic clients, which may be located anywhere on the Internet. To users, the client looks like any other application on their machine, only this one has immediate access to information all over the world. The pieces of information sent from servers to clients are known simply as documents, which may contain plain text, formatted text, graphics, sound, and other multimedia data.
The NCSA Mosaic system is an integrated set of browsers, viewers, servers, gateways, and filters that allow you to approach the Internet as one consistent information source. At the simplest level, the NCSA Mosaic clients provide navigation and document viewing capabilities for browsing the information universe of the Internet. As your interest, needs, and skills develop, the configurable addition of external viewers allows easy and straightforward expansion to handle virtually any specific type of data. This flexibility allows you to keep pace with the quickly evolving world of multimedia.
The NCSA Mosaic system is a completely open framework; you can enter at your most comfortable level, progress through the use of various viewers, learn to create your own hypertext documents, set up your own server, engage in multimedia collaboration with colleagues in distant locales, develop scripts for specialized information filtering and presentation, and develop gateways to unique information resources and integrate them into the NCSA Mosaic information space for other users. In short, the possibilities are endless; you can think of NCSA Mosaic and the Web as allowing the progressive customization of your own information space, and that of your group.
NCSA Mosaic is implemented for three types of platforms:- X Window System
- Macintosh
- Microsoft Windows
Each implementation takes advantage of the strengths of its respective platform, but they have all been implemented to preserve as much cross-system compatibility as possible. All three clients can be downloaded for personal use from NCSA's anonymous FTP server.
To use NCSA Mosaic as an Internet browser, the system on which it is installed must be fully connected to the Internet. This is because the first thing NCSA Mosaic usually does when you run it is download one of the NCSA Mosaic Home Pages (the startup document) from an NCSA server. If NCSA Mosaic executes but you get an error message instead of a home page, the problem is most likely in your Internet connection; you will have to get that connection established before you can use NCSA Mosaic to navigate the Internet.
Once you have successfully installed NCSA Mosaic, you should spend some time becoming familiar with the interface. The NCSA Mosaic Demo Document, available via a hyperlink in the NCSA Mosaic Home Page or via a menu selection, provides an overview of NCSA Mosaic's capabilities with hyperlinks to a wide variety of information sources. As you browse the information universe, you can access material through other menu selections and other home pages.
Lynx (The Web via a text-based browser)
Lynx is a general-purpose distributed information browser and is part of the World Wide Web project. Lynx was designed to support a Campus Wide Information System (CWIS), but can be used for many other applications.
When started, Lynx is given a local path specifying a file containing text to be displayed, or a Uniform Resource Locator (URL) that specifies a resource to be displayed (usually the name of a file containing text information), the type of server that will provide the resource, and the Internet address of the system on which the specified server is running.
When a hypertext document is being displayed, links appear different from standard text, and users press the up- or down-arrows to "select" a particular link. Selected links show up as highlighted text, and users press Return or the right arrow when a link is highlighted to "follow" the selected link. When the link is followed Lynx finds the associated file and displays it on the screen in place of the first file.
Lynx is available for most flavors of Unix and VMS. Lynx can currently be obtained by anonymous ftp from: ftp2.cc.ukans.edu in the pub/lynx directory.
A listserv list has been created for information about Lynx and for notification of updates.You may sign-up by sending a message with
subscribe lynx-dev your name
as the only line in the message to
listserv@ukanaix.cc.ukans.edu.
Miscellaneous Notes
In many electronic mail messages, it is sometimes useful to indicate that part of a message is meant in jest. It is also sometimes useful to communicate emotion which simple words do not readily convey. To provide these nuances, a collection of "smiley faces" has evolved. If you turn your head sideways to the left, :-) appears as a smiling face. Some of the more common faces are:
:-) smile :-( frown
:) also a smile ;-) wink
:-D laughing 8-) wide-eyed
:-} grin :-X close mouthed
:- smirk :-o oh, no!
What do "btw", "fyi", "imho", "wrt", and "rtfm" mean?
Often common expressions are abbreviated in informal network postings. These abbreviations stand for "by the way", "for your information", "in my humble [or honest opinion", "with respect to", and "read the fine manual".
Glossary
As with any profession, computers have a particular terminology all their own. Below is a condensed glossary to assist in making some sense of the Internet world.
Bibliography
A: Network Guides -- Books
This is a highly selective list. Books on "How to Use the Information Highway" are multiplying rapidly, and the end is not in sight. Each title listed below has been cited by at least one reviewer as among the best now available.
Bibliography
B: Network Guides -- FTP-able Documents
Electronic Internet guides are multiplying almost as rapidly as printed manuals. The dilemma, of course, is that you cannot fetch a guide on "how to use the 'Net" until you have learned at least a little about how to use the 'Net.
The full filenames are given, in the format
/directory/sub-directory(ies)/filename
You can get the file by using the full path name (including the slashes) or you can change directories one level at a time and browse along the way. If you see a related README file you should get and read it before you try to get the full file.
Note that almost all of these sites contain other documents. You may find the same items in several places. But not all will be the same versions, so remember check the date of anything you fetch.
The dates given are the latest of which I am aware. Updates could appear at any time.
internet-voyager-inf/
internet-voyager-1-2.txt
internet-voyager-2-2.txt
FILE: /pub/communications/internet-cmc
FILE: /pub/Net_info/Big_Dummy/bigdummy.txt
FILE: /pub/nic/medical.resources.xx-xx where xx-xx = latest release date
FILE: /pub/telecomputing-info/IRD/IRD-infusion-ideas.txt
FILES: /maasinfo/MaasInfo.TopIndex_1of2 /maasinfo/MaasInfo.TopIndex_2of2
FILE: /documents/rfc/rfc1402.txt
FILE: /pub/religion/electric-mystics-guide-v1.txt
NOTE: Volume 2 has not yet appeared
NOTE: Also via listserv@uottawa as MYSTICS V1-TXT
FILE: /pub/nic/infoguide.<
NOTE: Before you attempt to retrieve the guide, get and read the file 00-README FIRST.
JSE Homepage | Subscription Information | Current Issue | JSE Archive (1993-1998) | Data Archive | Index | Search JSE | JSE Information Service | Editorial Board | Information for Authors | Contact JSE | ASA Publications